目录第1章 kettle概述1.1 什么是kettle1.2 Kettle核心知识点1.2.1 Kettle工程存储方式1.2.2 Kettle的两种设计1.2.3 Kettle的组成1.3 kettle特点第2章 kettle安装部署和使用2.1 kettle安装地址2.2 Windows下安装使用2.2.1 概述2.2.2 安装2.2.3 案例2.3 创建资源库2.3.1 数据库资源库2.3.2 文件资源库
Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
1.2.1 Kettle工程存储方式
1) 以XML形式存储
2) 以资源库方式存储(数据库资源库和文件资源库)
1.2.2 Kettle的两种设计
简述:Transformation(转换):完成针对数据的基础转换。
Job(作业):完成整个工作流的控制。
区别:(1)作业是步骤流,转换是数据流,这是作业和转换的最大区别
(2)作业的每一个步骤,必须等到前面的步骤都跑完了,后面的步骤才会执行;而转换会一次性把所有控件全部先启动(一个空间对应启动一个线程),然后数据流会从第一个控件开始,一条记录,一条记录地流向最后的控件。

1.2.3 Kettle的组成
勺子(spoon.bat/spoon.sh):是一个图形化的界面,可以让我们用图形化的方式开发转换和作业。Windows选择spoon.bat;Linux选择spoon.sh煎锅(pan.bat/pan.sh):利用pan可以用命令行的形式调用Trans厨房(kitchen.bat/kitchen.sh):利用kitchen可以使用命令调用Job菜单(carte.bat/carte.sh):carte是一个轻量级的web容器,用于建立专用、远程的ETL Server
免费开源:基于Java的免费开源的软件,对商业用户也没有限制
易配置:可以在window、Linux、unix上运行,绿色无需安装,数据抽取高效稳定
不同数据库:ETL工具集,它允许你管理来自不同数据库的数据
两种脚本文件:transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制
图形化界面设计:通过图形化设计实现做什么业务,无需写代码去实现
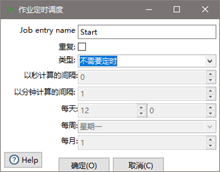
定时功能:在job下的start模块,有一个定时功能,可以每日、每周等方式进行定时。
官网地址
Home – Hitachi Vantara
下载地址
https://sourceforge.net/projects/pentaho/files/Data%20Integration/
kettle各版本国内镜像下载地址:http://mirror.bit.edu.cn/pentaho/(下载速度相对快一些)
2.2.1 概述
在实际企业开发中,都是在本地环境下进行kettle的job和Transformation开发的,可以在本地运行,也可以连接远程机器运行
2.2.2 安装
1) 安装jdk
2) 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
3) 双击Spoon.bat,启动图形化界面工具,就可以直接使用了
2.2.3 案例
1) 案例一 把stu1的数据按id同步到stu2,stu2有相同id则更新数据
(1)在mysql中创建两张表
mysql> create database kettle;
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));

(2)往两张表中插入一些数据
mysql> insert into stu1 values(1001,’zhangsan’,20),(1002,’lisi’,18), (1003,’wangwu’,23);
mysql> insert into stu2 values(1001,’wukong’);
mysql> insert into stu2 values(1001,’wukong’);

(3)在kettle中新建转换

(4)分别在输入和输出中拉出表输入和插入/更新

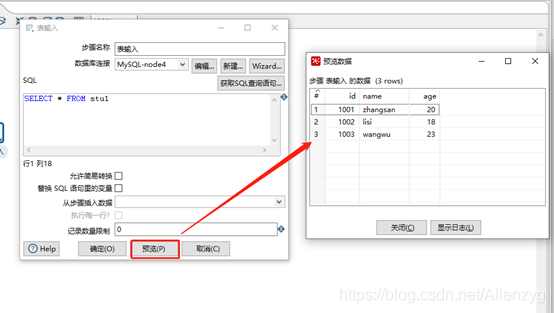
(5)双击表输入对象,填写相关配置,测试是否成功

(6)双击 更新/插入对象,填写相关配置
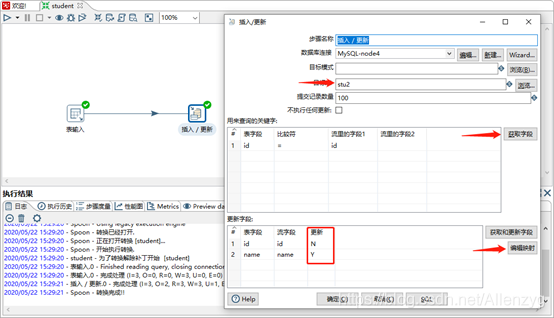
编辑映射,添加需要的字段,因为表stu2中没有age,所以不需要Add

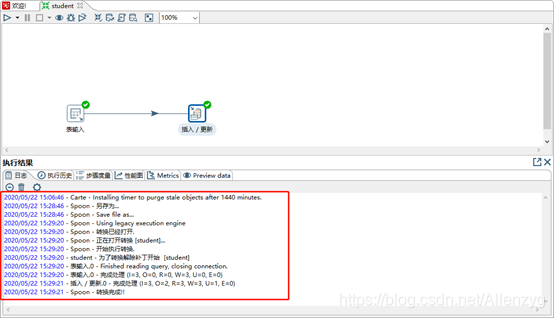
(7)保存转换,启动运行,去mysql表查看结果
注意:如果需要连接mysql数据库,需要要先将mysql的连接驱动包复制到kettle的根目录下的lib目录中,否则会报错找不到驱动。


2) 案例2:使用作业执行上述转换,并且额外在表stu2中添加一条数据
(1)新建一个作业

(2) 按图示拉取组件


(3)双击Start编辑Start
(4)双击转换,选择案例1保存的文件

(5)双击SQL,编辑SQL语句
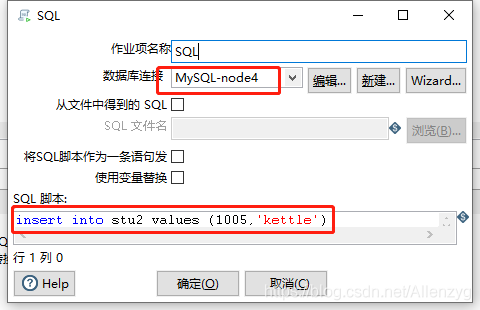
(6)保存执行
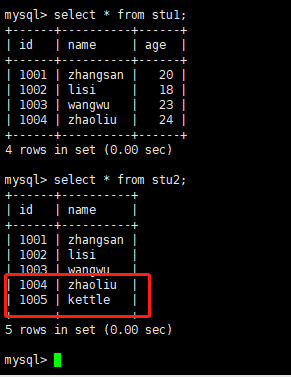
运行之前,查看数据:


运行之后查看结果:会发现除了刚才我们写的,insert语句之外,stu1表中的id为1004的也插入到stu2中了,因为我们执行了stu1tostu2.ktr转换。
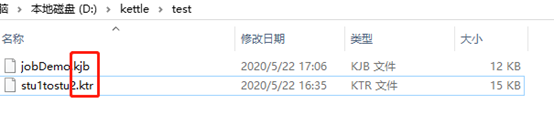
注:转换和作业的后缀不同
3)案例3:将hive表的数据输出到hdfs
(1)因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件从集群上拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下

注意:以上操作完,需要重启kettle才能生效
(2)启动hdfs,yarn,zookeeper,hbase集群的所有进程,启动hiveserver2服务
[root@node4 hadoop-2.6.4]# sbin/start-dfs.sh
[root@node4 hadoop-2.6.4]# sbin/start-yarn.sh

三台服务器分别开启HBase前启动Zookeeper
[root@node4 hadoop-2.6.4]# zkServer.sh start
[root@node5 hadoop-2.6.4]# zkServer.sh start
[root@node6 hadoop-2.6.4]# zkServer.sh start
开启hbase
[root@node4 hbase-1.2.3]# bin/start-hbase.sh

开启hive2
[root@node4 ~]# hiveserver2

(3)进入beeline,查看10000端口开启情况
[root@node4 ~]# beeline(回车)
Beeline version 2.1.0 by Apache Hive
beeline> !connect jdbc:hive2://node4:10000
Connecting to jdbc:hive2://node4:10000
Enter username for jdbc:hive2://node4:10000: root(输入用户名,回车)
Enter password for jdbc:hive2://node4:10000: ******(输入密码,回车)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive/apache-hive-2.1.0-bin/lib/hive-jdbc-2.1.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop/hadoop-2.6.4/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connected to: Apache Hive (version 2.1.0)
Driver: Hive JDBC (version 2.1.0)
20/05/23 20:05:58 [main]: WARN jdbc.HiveConnection: Request to set autoCommit to false; Hive does not support autoCommit=false.
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node4:10000>(到了这里说明成功开启10000端口)
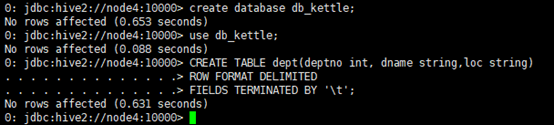
(4)创建两张表dept和emp
CREATE TABLE dept(deptno int, dname string,loc string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’;
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’;
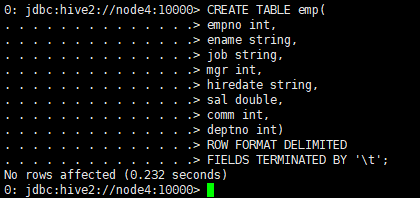
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’;
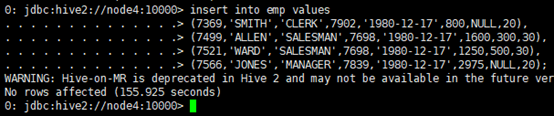
(5)插入数据
insert into dept values(10,’accounting’,’NEW YORK’),(20,’RESEARCH’,’DALLAS’),(30,’SALES’,’CHICAGO’),(40,’OPERATIONS’,’BOSTON’);

insert into emp values
(7369,’SMITH’,’CLERK’,7902,’1980-12-17′,800,NULL,20),
(7499,’ALLEN’,’SALESMAN’,7698,’1980-12-17′,1600,300,30),
(7521,’WARD’,’SALESMAN’,7698,’1980-12-17′,1250,500,30),
(7566,’JONES’,’MANAGER’,7839,’1980-12-17′,2975,NULL,20);
(6)按下图建立流程图

(7)设置表输入,连接hive
表输入1


表输入2

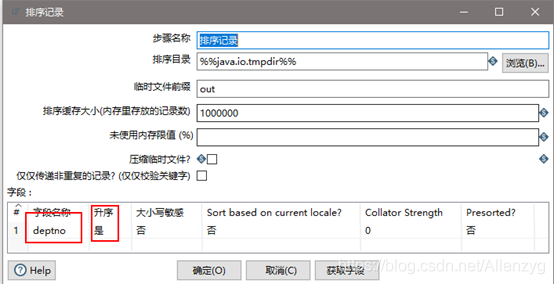
(8)设置排序属性
(9)设置连接属性
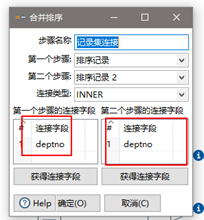
(10)设置字段选择
“选择和修改”、“元数据”什么都不操作即可,只操作“移除”。如果操作了“元数据”,那么要注意和“移除”比较一下,字段是否一致,不然会报错。


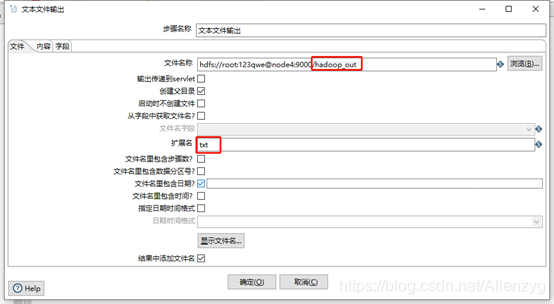
(11)设置文件输出



跟前端页面一致

(12)保存并运行查看hdfs
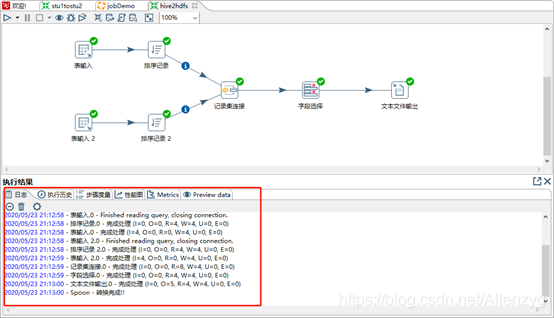
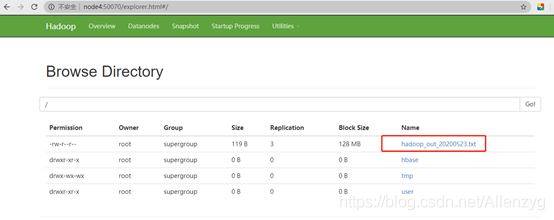
我们下载下来看一下:

4)案例4:读取hdfs文件并将sal大于1000的数据保存到hbase中
(1) 在HBase中创建一张表用于存放数据
[root@node4 ~]# hbase shell
hbase(main):002:0> create ‘people’,’info’
(2)按下图建立流程图

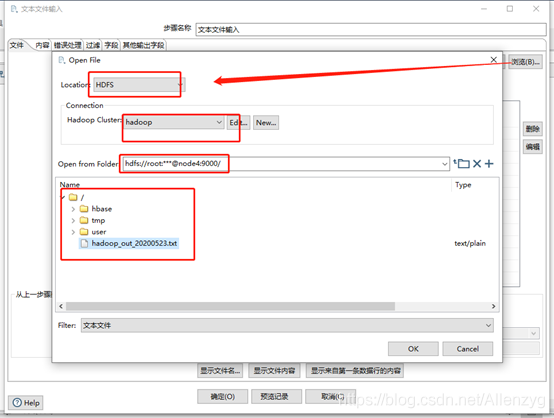
(3)设置文件输入,连接hdfs

(4)设置过滤记录

(5)设置HBase output


注意:若报错没有权限往hdfs写文件,在Spoon.bat中第119行添加参数
“-DHADOOP_USER_NAME=node4” “-Dfile.encoding=UTF-8”
(6) 保持并运行,查看hbase


2.3.1 数据库资源库
数据库资源库是将作业和转换相关的信息存储在数据库中,执行的时候直接去数据库读取信息,很容易跨平台使用
1)点击右上角connect,选择Other Resporitory
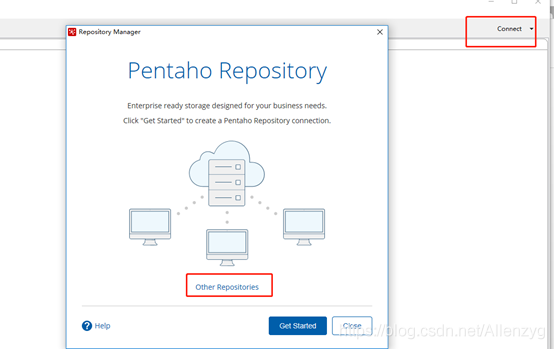
2) 选择Database Repository
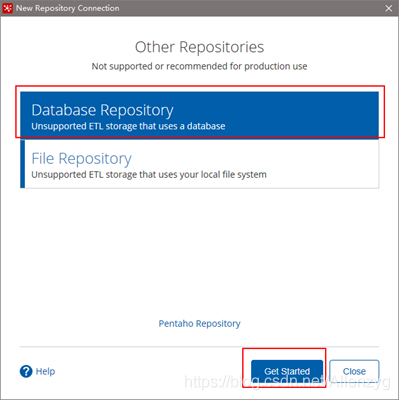
3) 建立新连接

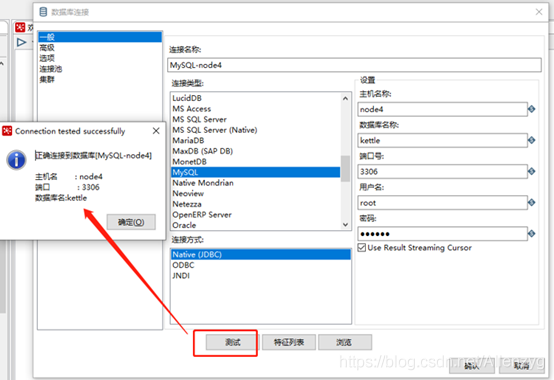
4) 填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成

5) 连接资源库
默认账号密码为admin

6) 将之前做过的转换导入资源库
(1)选择从xml文件导入

(2)随便选择一个转换

(3)点击保存,选择存储位置及文件名

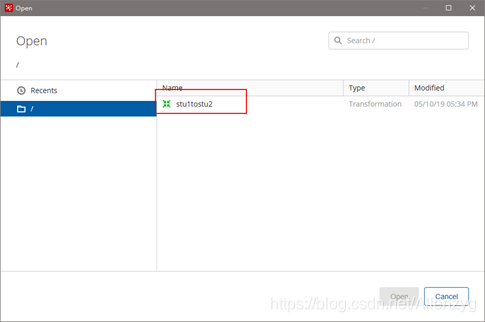
(4)打开资源库查看保存结果
2.3.2 文件资源库
将作业和转换相关的信息存储在指定的目录中,其实和XML的方式一样
创建方式跟创建数据库资源库步骤类似,只是不需要用户密码就可以访问,跨
平台使用比较麻烦
1)选择connect
2)点击add后点击Other Repositories

3)选择File Repository

4)填写信息

到此这篇关于kettle在windows上安装配置与实践案例的文章就介绍到这了,更多相关kettle在windows安装内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:Kettle下载与安装保姆级教程(最新)Kettle下载安装pdi-ce-7.1.0.0-12教程win10环境安装kettle与linux环境安装kettle的详细过程Kettle连接Oracle数据库方法((Oracle19c&Oracle11g))Kettle中使用JavaScrip调用jar包对文件内容进行MD5加密的操作方法通过Kettle自定义jar包供javascript使用kettle?入门使用教程(最新版)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章