
目录1.count 数据丢失2.distinct 数据丢失3.select 数据丢失4.导致空指针异常5.增加了查询难度扩展知识:NULL 不会影响索引总结
正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信息,如下图所示:
“兵马未动粮草先行”,看完了相关的配置之后,我们先来创建一张测试表和一些测试数据。
— 如果存在 person 表先删除
DROP TABLE IF EXISTS person;
— 创建 person 表,其中 username 字段可为空,并为其设置普通索引
CREATE TABLE person (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
mobile VARCHAR(13),
index(name)
) ENGINE=’innodb’;
— person 表添加测试数据
insert into person(name,mobile) values(‘Java’,’13333333330′),
(‘MySQL’,’13333333331′),
(‘Redis’,’13333333332′),
(‘Kafka’,’13333333333′),
(‘Spring’,’13333333334′),
(‘MyBatis’,’13333333335′),
(‘RabbitMQ’,’13333333336′),
(‘Golang’,’13333333337′),
(NULL,’13333333338′),
(NULL,’13333333339′);
select * from person;
DROP TABLE IF EXISTS person;
— 创建 person 表,其中 username 字段可为空,并为其设置普通索引
CREATE TABLE person (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
mobile VARCHAR(13),
index(name)
) ENGINE=’innodb’;
— person 表添加测试数据
insert into person(name,mobile) values(‘Java’,’13333333330′),
(‘MySQL’,’13333333331′),
(‘Redis’,’13333333332′),
(‘Kafka’,’13333333333′),
(‘Spring’,’13333333334′),
(‘MyBatis’,’13333333335′),
(‘RabbitMQ’,’13333333336′),
(‘Golang’,’13333333337′),
(NULL,’13333333338′),
(NULL,’13333333339′);
select * from person;
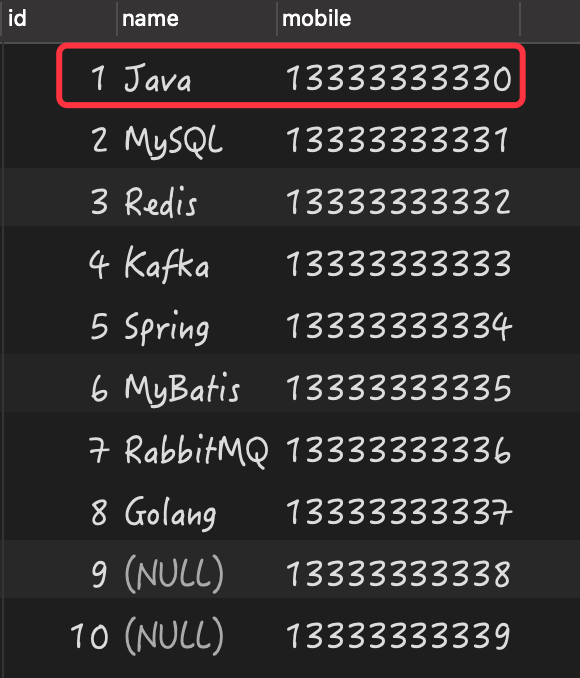
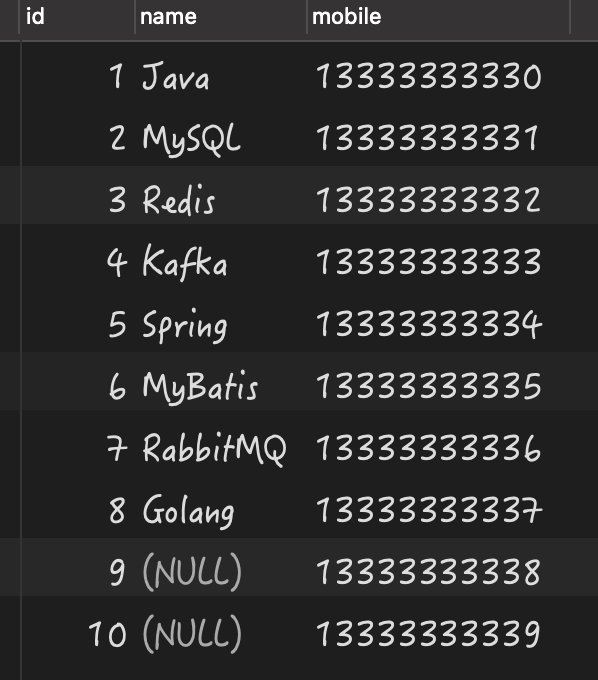
构建的测试数据,如下图所示:
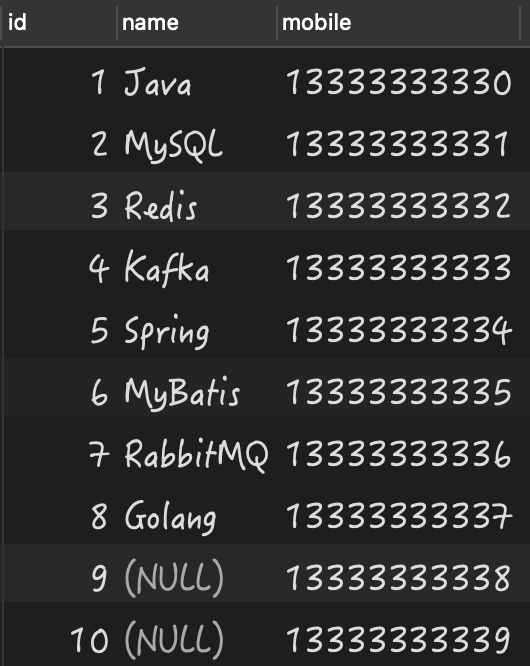
有了数据之后,我们就来看当列中存在 值时,究竟会导致哪些问题?
当某列存在 值时,再使用 查询该列,就会出现数据“丢失”问题,如下 SQL 所示:
select count(*),count(name) from person;
查询执行结果如下:
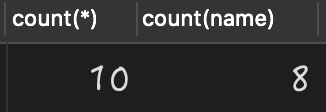
从上述结果可以看出,当使用的是 查询时,就丢失了两条值为 的数据丢失。
解决方案
如果某列存在 值时,就是用 进行数据统计。
扩展知识:不要使用 count(常量)
阿里巴巴《Java开发手册》强制规定:不要使用 count(列名) 或 count(常量) 来替代 count(),count() 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。
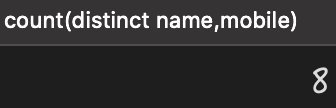
当使用 查询时,如果其中一列为 ,那么即使另一列有不同的值,那么查询的结果也会将数据丢失,如下 SQL 所示:
select count(distinct name,mobile) from person;
查询执行结果如下:
数据库的原始数据如下:

从上述结果可以看出手机号一列的 10 条数据都是不同的,但查询的结果却为 8。
如果某列存在 值时,如果执行非等于查询(<>/!=)会导致为 值的结果丢失。比如以下这个数据:
我需要查询除 name 等于“Java”以外的所有数据,预期返回的结果是 id 从 2 到 10 的数据,但当执行以下查询时:
select * from person where name<>’Java’ order by id;
— 或
select * from person where name!=’Java’ order by id;
— 或
select * from person where name!=’Java’ order by id;
查询结果均为以下内容:
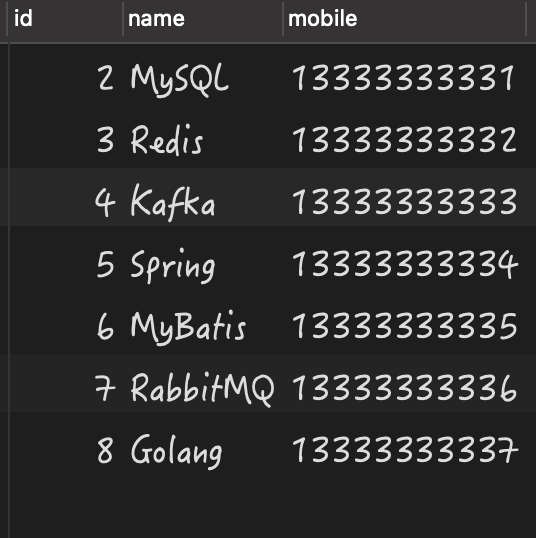
可以看出为 的两条数据凭空消失了,这个结果并不符合我们的正常预期。
解决方案
要解决以上的问题,只需要在查询结果中拼加上为 值的结果即可,执行 SQL 如下:
select * from person where name<>’Java’ or isnull(name) order by id;
最终的执行结果如下:

如果某列存在 值时,可能会导致 的返回结果为 而非 0,如果 查询的结果为 就可以能会导致程序执行时空指针异常(NPE),我们来演示一下这个问题。
首先,我们先构建一张表和一些测试数据:
— 如果存在 goods 表先删除
DROP TABLE IF EXISTS goods;
— 创建 goods 表
CREATE TABLE goods (
id INT PRIMARY KEY auto_increment,
num int
) ENGINE=’innodb’;
— goods 表添加测试数据
insert into goods(num) values(3),(6),(6),(NULL);
select * from goods;
DROP TABLE IF EXISTS goods;
— 创建 goods 表
CREATE TABLE goods (
id INT PRIMARY KEY auto_increment,
num int
) ENGINE=’innodb’;
— goods 表添加测试数据
insert into goods(num) values(3),(6),(6),(NULL);
select * from goods;
表中原始数据如下:

接下来我们使用 查询,执行以下 SQL:
select sum(num) from goods where id>4;
查询执行结果如下:
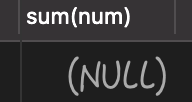
当查询的结果为 而非 0 时,就可以能导致空指针异常。
解决空指针异常
可以使用以下方式来避免空指针异常:
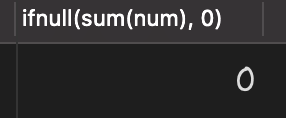
select ifnull(sum(num), 0) from goods where id>4;
查询执行结果如下:
当某列值中有 值时,在进行 值或者非 值的查询难度就增加了。
所谓的查询难度增加指的是当进行 值查询时,必须使用 值匹配的查询方法,比如 或者 又或者是 这样的表达式进行查询,而传统的 等这些表达式就不能使用了,这就增加了查询的难度,尤其是对小白程序员来说,接下来我们来演示一下这些问题。
还是以 表为例,它的原始数据如下:
错误用法 1:
select * from person where name<>null;
执行结果为空,并没有查询到任何数据,如下图所示:

错误用法 2:
select * from person where name!=null;
执行结果也为空,没有查询到任何数据,如下图所示:
正确用法 1:
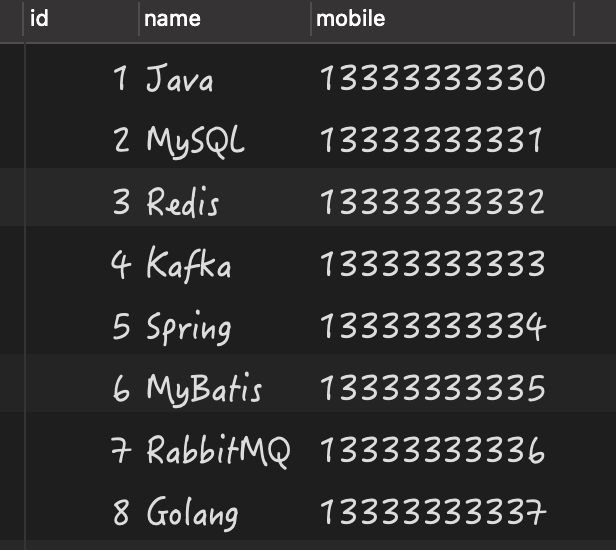
select * from person where name is not null;
执行结果如下:
正确用法 2:
select * from person where !isnull(name);
执行结果如下:
推荐用法
阿里巴巴《Java开发手册》推荐我们使用 来判断 值,原因是在 SQL 语句中,如果在 null 前换行,影响可读性;而 是一个整体,简洁易懂。从性能数据上分析 执行效率也更快一些。
细心的朋友可能发现了,我在创建 表的 字段时,为其创建了一个普通索引,如下图所示:
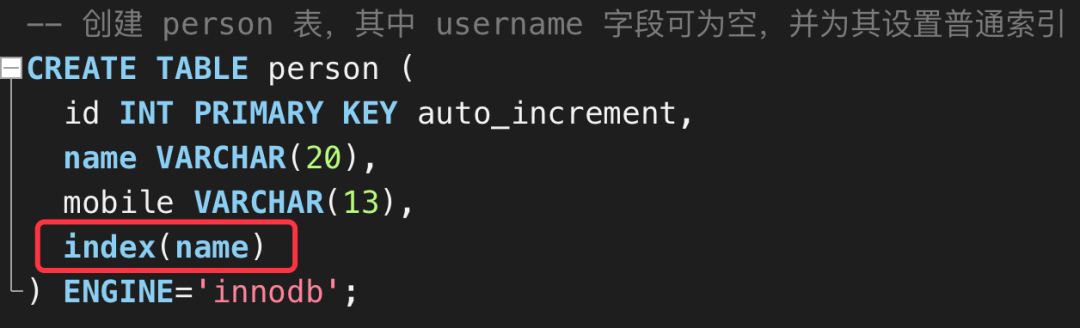
然后我们用 来分析查询计划,看当 中有 值时是否会影响索引的选择。
的执行结果如下图所示:

从上述结果可以看出,即使 中有 值也不会影响 MySQL 使用索引进行查询。
本文我们讲了当某列为 时可能会导致的 5 种问题:丢失查询结果、导致空指针异常和增加了查询的难度。因此在最后提倡大家在创建表的时候尽量设置 的约束,如果某列确实没有值,可以设置空值(’’)或 0 作为其默认值。
最后:大家还有因为 NULL 而造成的各种坑吗?欢迎评论区补充留言。
到此这篇关于MySQL字段为 NULL的5大坑的文章就介绍到这了,更多相关MySQL字段为NULL内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:MySQL中查询字段为空或者为null的方法Mysql字段为null的加减乘除运算方式详解MySQL的字段默认null对唯一索引的影响mysql实现批量修改字段null值改为空字符串mysql字段为NULL索引是否会失效实例详解mysql 字段定义不要用null的原因分析为什么mysql字段要使用NOT NULLMySQL中可为空的字段设置为NULL还是NOT NULLmysql 求解求2个或以上字段为NULL的记录MySQL查询空字段或非空字段(is null和not null)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

